PTE官方培训提示——PTE口语声波对练习不要拖音!
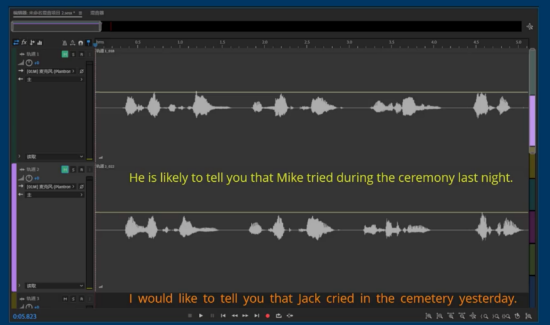
首先,官方提到了市面上很流行的一种指导方法就是声波对比。也就是说老师让学生录一段口语,然后用学生的声波跟所谓的满分声波作为对比。这种方法可以粗略观察一个考生的声能和发声习惯,但是完全当做评分依据是不靠谱的。如图:

上图为所谓的满分声波,下图为学生的模仿音频。将声波图放到专业软件中我们会发现,声波图只可以提供一些信息比如音量,停顿,节奏(也就是音强),但对于音调,音色,也就是说你到底读的内容是什么其实并不准的。
通过这节官方公开课我们可以了解到,培生的识别引擎是以单词为单位来进行建模。将语图进行数字化处理。那么每个单词里可以分为若干个音素,举例如图所示
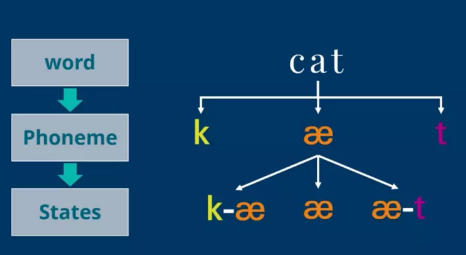
Cat这个单词分为3个音素,那么每个音素又都会分为不同的过程。这之中元音的频率是相对比较平稳的,但辅音又会稍微复杂一些。另外在实际的语流中,每个音又会受到前后相邻音的影响(这是英文发音的基本规则,与机器无关),所以每个音的发音前段,中端和尾端其实频率会有所偏差。那么培生的评分过程就是把考生的录音做很细致的切片,反向把每个状态拼成音素,再把音素拼成单词。从这点我们需要注意的是:拖音可能造成的评分下降往往要比吞音现象,同学们在练习的时候尽可能不要拖音。